Data Science in the book publishing industry – To be or not to be

(Originally posted on ALDUS, on October 12th, 2016)
Data – the backbone of every digital industry
Every industry you can think of is either digital, mostly digital or being transformed as you read this. Publishing is not an exception. From the moment digital tools are involved in crafting, distributing and selling products, the business opportunities grow exponentially, as well as potential risks and challenges.One of the well known facts of a process becoming digital is that suddenly, almost every step of the way can be measured, and its related data pieces stored and analyzed. While this was well known at least since Edgard Codd invented the relational model for databases in 1970, and by the end of the nineties everyone was using relational databases everywhere, there were several elements evolving at the same time that would change how we approach data in the last years. First, the advent of the web meant that millions of pages and therefore of potentially important information was publicly available: legal documents, patents, competitive data, etc. Secondly, social networks and Web 2.0 sites multiplied the amount of user-generated content that, while noisy, had gems of information for companies and institutions, like in the areas of reputation or digital footprint. Thirdly, the price of storage continued going down at an accelerated pace and cloud services started making it extremely easy and cheap to store more and more information and to process it much more quickly. For many digital companies, there is now no need to compress or remove datasets because of storage price. Fourth, new technologies and algorithms appeared, such as MapReduce or NoSQL databases, that changed the way data was processed. Lastly, previously abandoned data processing technologies and algorithms like Neural Networkswere revamped and with some changes and the use of the advanced computing and storage, showed their real potential.
Data Science, the concept that now comprises all types of data acquisition, processing and visualization a company requires, has become a cornerstone in industries such as transportation, finance, films, medicine or retail. Is it true for publishing as well?
Publishing and Data
In the last few years there is an increasingly ongoing discussion about how and whether data truly affects publishing, authors and readers. And if so, WHY. There are some articles and talks in conferences about publishing and data, and undoubtedly the interest has grown steadily in the last couple of years. In the past, discussions had been mostly focused on Metadata and SEO, two critical aspects of data that have still no clear solution in publishing. There were also some talks about understanding the readers’ behavior while reading, which could be used to offer better products and value-added services, but were typically biased towards the fear of data protection; something we all need to be aware and respectful of, but cannot prevent us from assessing the potential benefits.In the meantime, while publishers and agents are still thinking about whether or not this makes sense, the big retailers were hectically implementing new algorithms and services that take advantage of the information provided by sales and user behavior. Amazon’s recommendation algorithm is just the peak of everything they could do with all the info they have from the users’ purchasing habits. But are they the only players in the industry that can take advantage of data? Certainly not, and there are some initiatives that show it, like Penguin Random House UK’sconsumer insight efforts, Trajectory’s data science work on semantic content, Jellybooks’ client-side tracking of reader behaviour for focus groups, Bookmetrix’s altmetric dashboard (currently only available to Springer staff), Tekstum’s sentiment and emotion analysis on books, Linkgua’s work on semantics as well, Bibblio’s content-based recommendation or Kadaxis’ intelligent book keyword analysis.
Web analytics is not enough
Many companies, not just in the publishing ecosystem, have spent much of their data-related time on web analytics. Giving importance to web analytics is good, and has been a great way for companies to start obtaining value from the information that comes from the behaviour of their users.In the last years, some interesting methodologies and frameworks have appeared – I’m quite keen on Dave McClure’s AARRR model, but there are some others- that help organize the metrics and analytics.
But it is not enough. Thinking in business terms, all current companies are, at one stage or another, using web analytics. So all companies know how their consumers make use of their web sites, their conversion rates, whether they leave the website quickly or not… and most of those also understand the importance of mobile. While critical, this provides no competitive advantage anymore.
Some other companies are starting to look further. They are starting to store, and then analyze, as much data as possible about their users and processes.
In 24symbols, a subscription service for e-books and audiobooks, we use Google Analytics and some other tools to learn about the number of visits, users or pageviews we get; the conversion rates from visitors to registrations; relatively complex goals to learn about micro conversions such as visiting one or the other page. But we also store and analyze the information of our readers. This is all treated confidentially and managed in an aggregate manner. We don’t care that much about what Joe or Jane Doe are doing, but we certainly do about the behavior of the cohorts or segments they belong to, like the month and year they signed up, geography, gender, etc.
We then work on this information intensively. We started with simple stats and charts that grew up to more than two hundred different metrics available – though, as many of the methodologies recommend, we don’t monitor more than a few at a time. And we are now working on more advanced analysis like forecasting and recommendations by using everything from more statistics to machine learning algorithms or clustering and even Deep Learning.
This is where the new concepts such as Big Data or Data Science come into play. While many of these new words are just buzzwords made up to create new expectations, the truth is that as data becomes one of the cornerstone of any business, along with processes and software, management of complex and/or huge datasets and the knowledge, tools and processes required to process them are creating a corpus that, if not at full extent, needs to be understood by any company that wants to be alive in five years. Their competitors are already working on it.
Me, myself and I?
Of course, the perfect situation for stakeholders in the publishing industry would be to obtain all the data themselves so they can process it at their leisure. But this is not how the current world works. For instance, this would require publishers to have direct access to consumers, which is only possible and feasible for a very limited amount of them, those that are really recognizable to the public. As much as Big 5 companies try to create their own consumer websites, people just don’t enter a bookstore to buy a “HarperCollins” or a “Random House” book. But this is not just a problem for publishers. As a small retailer, 24symbols do not store the credit card information of their users as that would mean an increase in the level of data protection that we cannot assume. So we delegate that, as 99% of e-commerce companies do, to a third party with the appropriate levels of security and data protection mechanisms, at the cost of losing access to really interesting data. Distributors have quite a lot of data coming from retailers and publishers, and some of them, like Vearsa, are using it to offer new advanced services to publishers, but they do not know anything about the actual behaviour of the potential readers.This should not be surprising, as the publishing industry is a quite evolved one where the value chain has matured to a quite disaggregated point, where each stakeholder is quite interested in keeping as much knowledge as possible to itself. Nobody has a clear view of what is going on, just like the fable of the blind men and the elephant.
What we at 24symbols have learned is that the information from retailers and services that face the audience is critical for the publishers. Without going into individual consumer details, aggregate data can be used to learn much more about how and when people read the publishers’ books; to find correlations among reader segments; or to understand the actual and real success and failure rates of the titles, beyond sales or subjective comments. But just a very limited number of retailers are willing to work with publishers and provide this information. And, at the same time, just a few publishers have the time and knowledge to fully understand the value of this information.
But what if a publisher does not have the readers’ information? Should it just quit on data? Not at all! There are many other non-trivial areas where data is critical:
- Analyze the titles and compare them to those of its competitors (something Bookmetrix, 24symbols or Textum are already working on.)
- Improve its sales forecast with prediction analysis.
- Fully understand the importance and reach of social networks for each of its book campaigns.
- Does the publisher know how the quality of its metadata affects the results of the titles in the different channels?
- Sentiment analysis on public comments in social networks, blogs and retailers on their titles and compared to those of its competitors.
How to start – roles, tasks and tools
If publishers dealing with the new digital reality are struggling to incorporate technical roles to their teams, working with data is even harder, as one can be overwhelmed with some much information about statistics, algorithms, neural networks and tools that change every two months. Look at the image below that shows just some of the techniques, algorithms, theories and tools a Data Scientist should know.In addition, finding data scientists is becoming hard and expensive. A freshly-minted data scientist in the US may have a starting salary of USD 90,000 and while in old Europe this salary may be lower, it will still be a big burden for small and mid-size publishers. The trick here is to start small and evolve iteratively. Find someone on your existing team that is not afraid of pulling his/her sleeves and learning while working; in the meantime, get help from a partner or someone who actually knows about data and start playing around. For instance, 24symbols provide near-real-time data about the publisher’s title reads. This is a great chance for many publishers to start thinking about what they need.
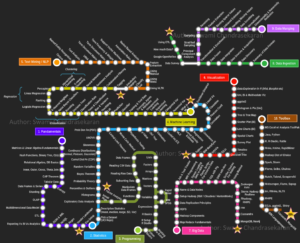
A second stage is to compare this with the information they had. Does this data match the expectations they had? Do the “number of reads” or “number of pages” metrics match the “classic sales ranking”? If not, why? Can we establish new hypothesis about our business, and use the current or newer metrics to help validate it?
A third stage, of course, is to decide what else is needed, what worked and what didn’t.
And then, rinse and repeat ?
As you can see in the image below, there are hundreds of tools you can use. But do not despair, Microsoft Excel will probably be the first one you need. And then some R or Python, languages that are fully documented and with quite advanced tools and online courses to make the learning curve easier.

Conclusions
A caveat of working with data is that it is very easy to forget about why we started to look into a specific dataset and just dive deep and deeper into it. Business goals must be clear and they need to be in everyone’s minds at all time -though without disregarding the magic of how exploratory analysis may help us find unexpected reasons or challenges-.But without data, players in the publishing industry are blind to many of the challenges that are and will be facing in the following years, with more sophisticated readers, incumbents from other related industries taking advantage of their own knowledge of what people want when looking for mobile and digital culture and entertainment, and more complex internal processes that require deeper understanding.
Beyond the buzzwords, data is here to stay. In publishing, we should all forget about discussions on “Big Data” or “Artificial Intelligence” and focus on what we need from data, where can we find it and what we need to know to squeeze the useful nuggets out ofit for good data-informed business decisions.
Photo credits: https://www.flickr.com/photos/nhoffman/3910306929/

Comments