Information Retrieval (3): la arquitectura básica
Una vez tenemos claro que lo que requerimos es información que nos provea, de alguna manera, de conocimiento (como ya dije, es matizable, pero podemos partir de ahí), quiero entrar en el meollo de la recuperación de información web. Para ello, qué mejor que comentar la arquitectura básica de un buscador actual.
Podemos definir la arquitectura de un buscador web como el trabajo en equipo de dos componentes totalmente diferentes:
1. El indexador
2. El buscador
1. El indexador es el componente que se ocupa de acceder a la información (en este caso web) y procesar su contenido y contexto para almacenar en un repositorio todo lo necesario para que luego la búsqueda sea la más adecuada. Es un proceso generalmente offline, debido a la gran cantidad de información existente en la web (como un texto cuya referencia no recuerdo ahora:
"Summarizing, the Web is a huge text, distributed in a low quality network, with poorly written content, non focused, without a good organization, and queried by non-expert users"). Este componente se suele dividir en dos: el propio indexador y el "Web Crawler", el motor de navegación que accede a cada una de las página que deseamos procesar, o que el "crawler" encuentra.
2. El buscador es la parte visible de estas herramientas. Se ocupa, en tiempo real generalmente, de atender las peticiones de los usuarios y acceder al índice creado por el módulo indexador para mostrar aquellos resultados que más se ajustan a lo requerido. Dependiendo del indexador y de las estrategias de búsqueda implementadas, la calidad y cantidad de respuestas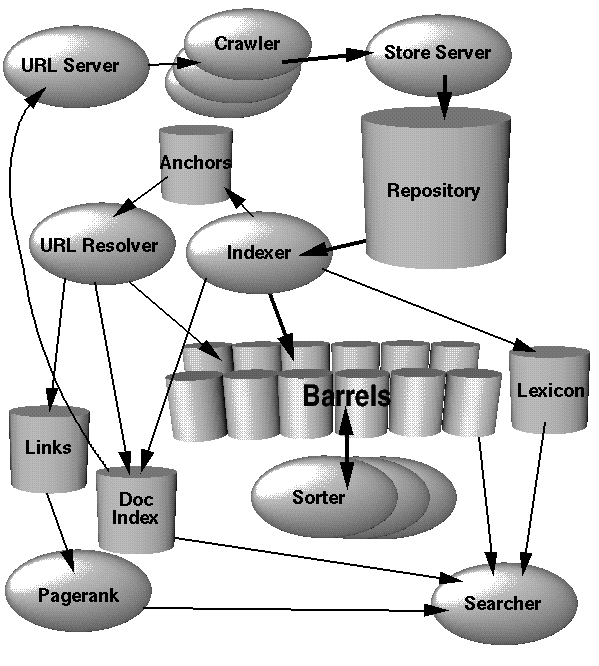 puede variar enormemente; podemos encontrarnos buscadores que sencillamente aceptan palabras clave y devuelven aquellos resultados (enlaces a páginas web) que contienen esas palabras, hasta entornos personalizados que realizan gran cantidad de procesamiento tanto sobre la estructura de la búsqueda como del contexto en el que se realiza para ofrecer documentos más ajustados a lo que quería un usuario (recordemos que debido a que estas herramientas de búsqueda suelen ofrecerse a un público mayoritario, el conocimiento medio de técnicas de búsqueda avanzada será bastante bajo).
puede variar enormemente; podemos encontrarnos buscadores que sencillamente aceptan palabras clave y devuelven aquellos resultados (enlaces a páginas web) que contienen esas palabras, hasta entornos personalizados que realizan gran cantidad de procesamiento tanto sobre la estructura de la búsqueda como del contexto en el que se realiza para ofrecer documentos más ajustados a lo que quería un usuario (recordemos que debido a que estas herramientas de búsqueda suelen ofrecerse a un público mayoritario, el conocimiento medio de técnicas de búsqueda avanzada será bastante bajo).
Enlazo a la imagen del sistema original de Larry Page, uno de los fundadores de Google, llamado BackRub, que sigue de manera bastante fiel la arquitectura básica de un motor de búsqueda. Poco a poco iré explicando la necesidad de algunas de las cajas que aparecen por ahí :)
Podemos definir la arquitectura de un buscador web como el trabajo en equipo de dos componentes totalmente diferentes:
1. El indexador
2. El buscador
1. El indexador es el componente que se ocupa de acceder a la información (en este caso web) y procesar su contenido y contexto para almacenar en un repositorio todo lo necesario para que luego la búsqueda sea la más adecuada. Es un proceso generalmente offline, debido a la gran cantidad de información existente en la web (como un texto cuya referencia no recuerdo ahora:
"Summarizing, the Web is a huge text, distributed in a low quality network, with poorly written content, non focused, without a good organization, and queried by non-expert users"). Este componente se suele dividir en dos: el propio indexador y el "Web Crawler", el motor de navegación que accede a cada una de las página que deseamos procesar, o que el "crawler" encuentra.
2. El buscador es la parte visible de estas herramientas. Se ocupa, en tiempo real generalmente, de atender las peticiones de los usuarios y acceder al índice creado por el módulo indexador para mostrar aquellos resultados que más se ajustan a lo requerido. Dependiendo del indexador y de las estrategias de búsqueda implementadas, la calidad y cantidad de respuestas
puede variar enormemente; podemos encontrarnos buscadores que sencillamente aceptan palabras clave y devuelven aquellos resultados (enlaces a páginas web) que contienen esas palabras, hasta entornos personalizados que realizan gran cantidad de procesamiento tanto sobre la estructura de la búsqueda como del contexto en el que se realiza para ofrecer documentos más ajustados a lo que quería un usuario (recordemos que debido a que estas herramientas de búsqueda suelen ofrecerse a un público mayoritario, el conocimiento medio de técnicas de búsqueda avanzada será bastante bajo).Enlazo a la imagen del sistema original de Larry Page, uno de los fundadores de Google, llamado BackRub, que sigue de manera bastante fiel la arquitectura básica de un motor de búsqueda. Poco a poco iré explicando la necesidad de algunas de las cajas que aparecen por ahí :)

Comments
Al no hacerlo sobrecargas otros servidores (alguno de ellos mantenidos por personas con cargo a su propio bolsillo).
Hay quien llama a esta práctica "robo de ancho de banda" (algo pomposo, lo se, peeeerooo) y está mal visto en general.
http://en.wikipedia.org/wiki/Bandwidth_theft
-J
Al menos, pasábamos horas hablando por teléfono :p
Hwe conocido a personas que han sufrido por este tema, ya se que nesto no lo lee mucha gente y que son cosas bastante especializadas (no es la típica coña que miles de personas enlazan), pero bueno, por higiene en los modales... y por sacar el tema.
Un poco de proselitismo no viene mal en esto, y a lo mejor alguien que no lo conocía lo ha descubierto.
Saludos erforeros.
Oído cocina. Además, cuando sea referenciado por BoingBoing (aunque siga escribiendo en castellano) tendré que estar preparado :)